Meta has taken the wraps off its latest advancement in the realm of large language models (LLMs) with the introduction of Llama 3. This groundbreaking model boasts two distinct variations, each with its own parameter count: 8 billion and 70 billion. Llama 3 is set to make its presence known across a diverse range of platforms, including AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake.
While Llama 3 is currently limited to text-based responses, Meta has emphasized the significant leap forward in response quality compared to its predecessor. According to the shared information, Llama 3’s responses to queries exhibit greater diversity, showcasing enhanced reasoning capabilities. Additionally, Meta highlights Llama 3’s improved ability to comprehend instructions and generate code.
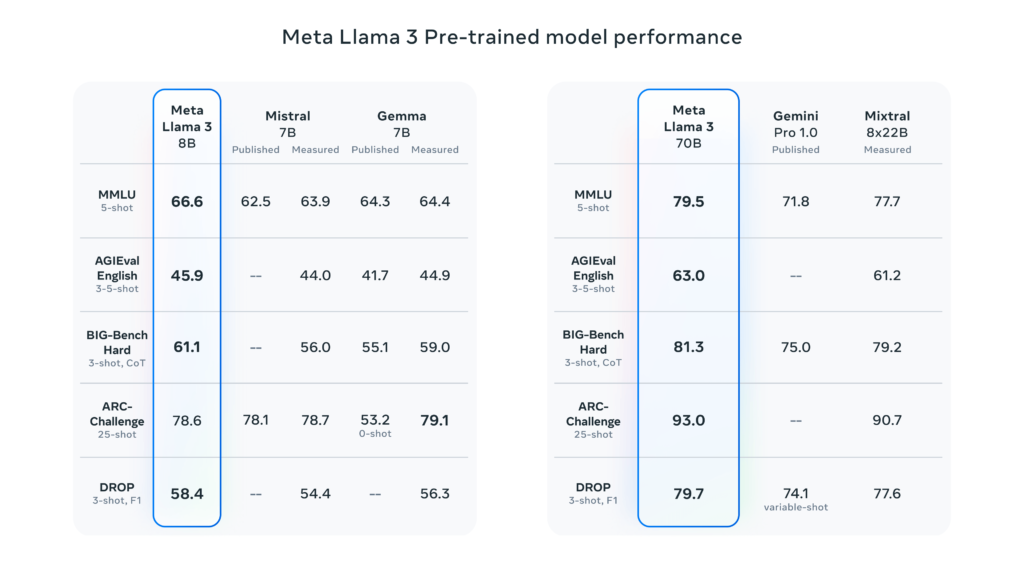
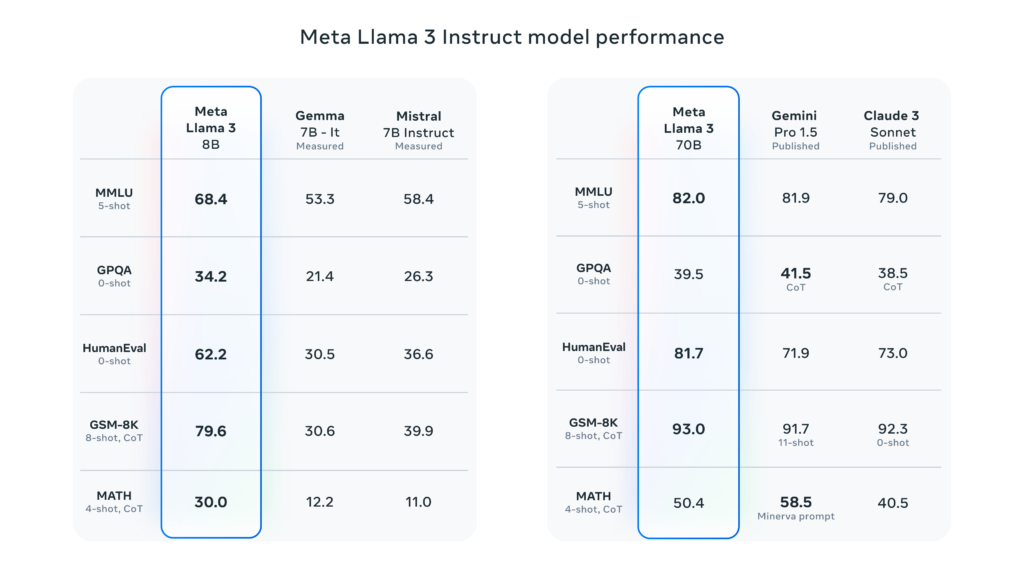
Meta’s blog post accompanying the release features a comparison table showcasing Llama 3’s performance against other models. In specific benchmark tests, both sizes of Llama 3 outperform similarly sized models like Google’s Gemma and Gemini, Mistral 7B, and Anthropic’s Claude 3.
In the MMLU benchmark, which generally measures general knowledge, Llama 3 8B outperforms Gemma 7B and Mistral 7B by a significant margin. Similarly, Llama 3 70B narrowly edges out Gemini Pro 1.5. However, it’s worth noting that Gemini Pro 1.5 takes the lead in GPQA and MATH criteria. Interestingly, Meta’s detailed post makes no mention of OpenAI’s flagship model, GPT-4.
In a New York Times article, Kevin Roose argues that AI benchmarking tests are inadequate for comparing models. Roose points out that the datasets used for training sometimes contain answers to benchmark questions, allowing models to game the tests.
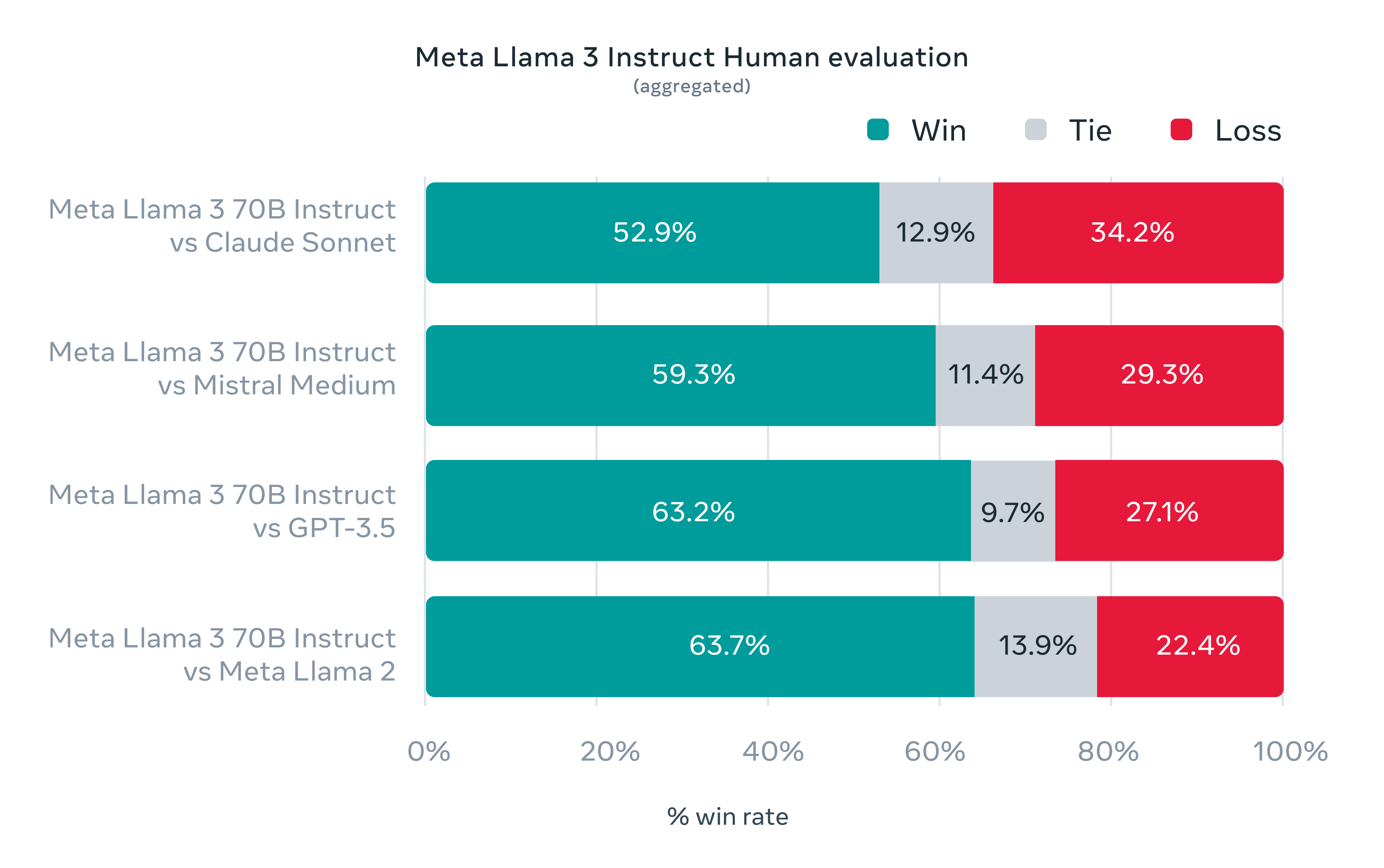
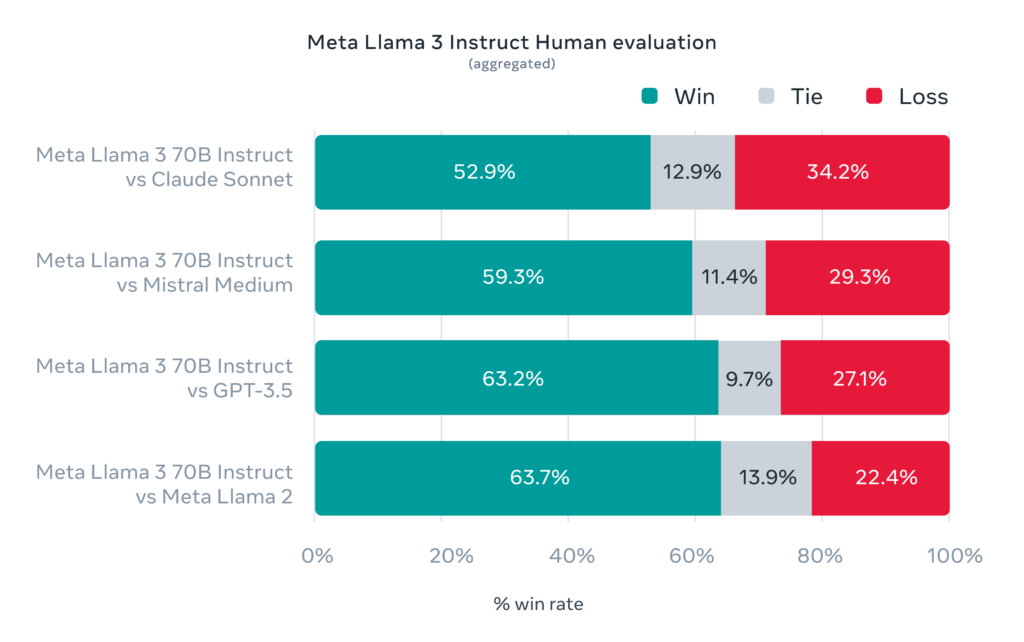
Despite these concerns, Meta’s evaluation, conducted by human assessors, indicates that Llama 3 outperforms other models, including OpenAI’s GPT-3.5. In this regard, Meta has created a new dataset for evaluators, designed to mimic real-world use cases for Llama 3. This dataset encompasses scenarios like requesting advice, summarizing, and creative writing. The company emphasizes that the team working on the model did not have access to this new evaluation data, ensuring it did not influence the model’s performance.
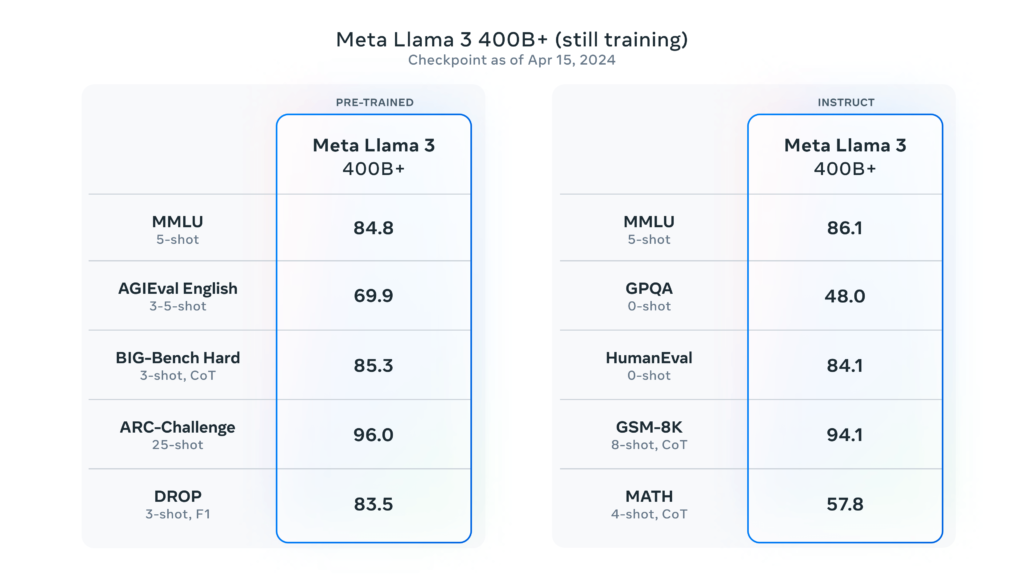
Meta is also working on a larger multimodal version of Llama 3 with a massive parameter count of over 400 billion. This new Llama 3 variant is still under development, but it is expected to be capable of learning more complex patterns compared to its smaller counterparts.
Key Highlights of Llama 3:
- Two variants: 8 billion and 70 billion parameter models
- Available on various platforms: AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake
- Improved response quality compared to the previous version
- More diverse and well-reasoned responses to queries
- Enhanced ability to understand instructions and generate code
- Outperforms similar-sized models in benchmark tests
- Meta has created a new evaluation dataset to assess real-world performance
- A larger multimodal version with over 400 billion parameters is under development








